背景
什么是 dependency parsing
- 通过分析语言单位内成分之间的依存关系揭示其句法结构。即识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间关系。
- 句法分析(symentic parsing)= 句法结构分析(syntactic structure parsing)+ 依存关系分析(dependency parsing)。
- 成分结构分析(constituent structure parsing)以获取整个句子的句法结构或者完全短语结构为目的的句法分析,又称短语结构分析(phrase structure parsing);
- 依存分析(dependency parsing)以获取局部成分为目的的句法分析。
目前的句法分析已经从句法结构分析转向依存句法分析,一是因为通用数据集Treebank(Universal Dependencies treebanks)的发展,虽然该数据集的标注较为复杂,但是其标注结果可以用作多种任务(命名体识别或词性标注)且作为不同任务的评估数据,因而得到越来越多的应用,二是句法结构分析的语法集是由固定的语法集组成,较为固定和呆板;三是依存句法分析树标注简单且parser准确率高。
有哪些应用
主要是句法分析的应用,如机器翻译、信息检索与抽取、问答系统、语音识别。
在项目中使用的:NER(挖掘新词)
如何描述语法
有两种主流观点,其中一种是短语结构文法,英文术语是:Constituency = phrase structure grammar = context-free grammars (CFGs)。
这种短语语法用固定数量的rule分解句子为短语和单词、分解短语为更短的短语或单词……
从 none phrase 开始,后面可能会有 adjective none、prepositiontial phrase(可能又依赖于其他名词短语),
另一种是依存结构,用单词之间的依存关系来表达语法。如果一个单词修饰另一个单词,则称该单词依赖于另一个单词
细节
人们画依存句法树的弧的方式不同,这门课是head指向dependent(即箭头指向的词语是依赖者,箭头尾部的词语是被依赖者)。
每个句子都有一个虚根,代表句子之外的开始,这样句子中的每个单词都有自己的依存对象了。

可用的特征
- 双词汇亲和(Bilexical affinities),比如discussion与issues。
- 词语间距,因为一般相邻的词语才具有依存关系
- 中间词语,如果中间词语是动词或标点,则两边的词语不太可能有依存
- 词语配价,一个词语最多有几个依赖者。
约束
- ROOT只能被一个词依赖。
- 无环。
方法
Dynamic programming
估计是找出以某head结尾的字串对应的最可能的句法树。
Graph algorithms
最小生成树。
Constraint Satisfaction
估计是在某个图上逐步删除不符合要求的边,直到成为一棵树。
“Transition-based parsing” or “deterministic dependency parsing”
greedy choice of attachments guided by ml clf.
主流方法,基于贪心决策动作拼装句法树。
step 2: train a classifier
已经有了 a tree bank with parses of sentences, 就根据 tree bank 来确定 which sequence of operations would give the correct parse of a sentence (transition的分类问题)
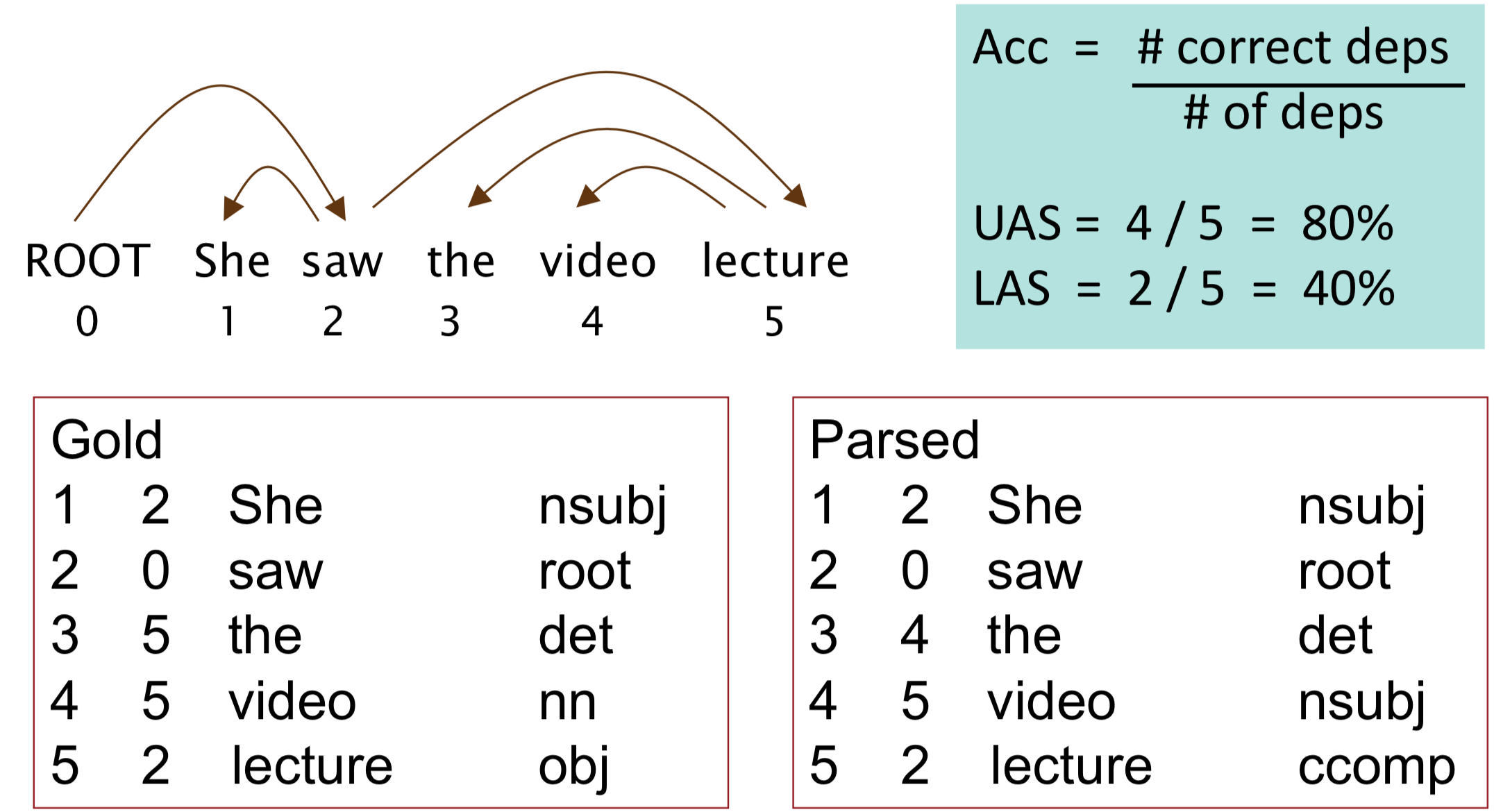
Unlabeled attachment score(UAS)= head
Labeled attachment score(LAS) = head and label
简单实现
1 | import sys |
调用函数试一下:
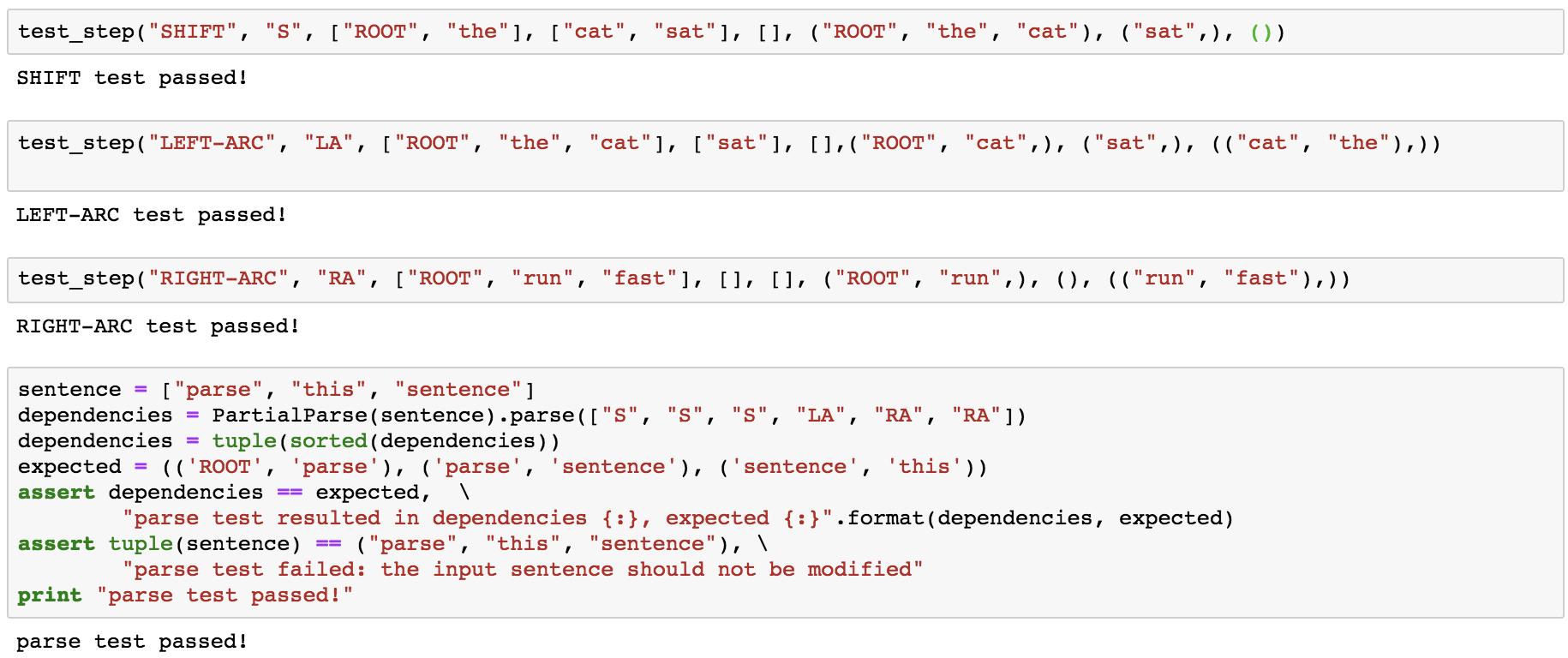
Our network will predict which transition should be applied next to a partial parse. We could use it to parse a single sentence by applying predicted transitions until the parse is complete. However, neural networks run much more efficiently when making predictions about batches of data at a time (i.e., predicting the next transition for a many different partial parses simultaneously). We can parse sentences in minibatches with the following algorithm.
就是一个parser一次处理一个sentence,怎么能批量处理 sentences ~~ miniBatch ~~

写个程序试一下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53import copy
def minibatch_parse(sentences, model, batch_size):
"""Parses a list of sentences in minibatches using a model.
Args:
sentences: A list of sentences to be parsed (each sentence is a list of words)
model: The model that makes parsing decisions. It is assumed to have a function
model.predict(partial_parses) that takes in a list of PartialParses as input and
returns a list of transitions predicted for each parse. That is, after calling
transitions = model.predict(partial_parses)
transitions[i] will be the next transition to apply to partial_parses[i].
batch_size: The number of PartialParses to include in each minibatch
Returns:
dependencies: A list where each element is the dependencies list for a parsed sentence.
Ordering should be the same as in sentences (i.e., dependencies[i] should
contain the parse for sentences[i]).
"""
partial_parses = [PartialParse(s) for s in sentences]
unfinished_parse = copy.copy(partial_parses)
while len(unfinished_parse) > 0:
minibatch = unfinished_parse[0:batch_size]
# perform transition and single step parser on the minibatch until it is empty
while len(minibatch) > 0:
transitions = model.predict(minibatch)
for index, action in enumerate(transitions):
minibatch[index].parse_step(action)
minibatch = [parse for parse in minibatch if len(parse.stack) > 1 or len(parse.buffer) > 0]
# move to the next batch
unfinished_parse = unfinished_parse[batch_size:]
dependencies = []
for n in range(len(sentences)):
dependencies.append(partial_parses[n].dependencies)
return dependencies
class DummyModel(object):
"""Dummy model for testing the minibatch_parse function
First shifts everything onto the stack and then does exclusively right arcs if the first word of
the sentence is "right", "left" if otherwise.
"""
def predict(self, partial_parses):
return [("RA" if pp.stack[1] is "right" else "LA") if len(pp.buffer) == 0 else "S" for pp in partial_parses]
def test_dependencies(name, deps, ex_deps):
"""Tests the provided dependencies match the expected dependencies"""
deps = tuple(sorted(deps))
assert deps == ex_deps, \
"{:} test resulted in dependency list {:}, expected {:}".format(name, deps, ex_deps)
