词语的表示
- discrete representation (similar to symbolic )
- symbolic representations(localist representation, one-hot representation)
- distributed representations
- Distributional similarity based representations
两种产生词向量的方法
- Skip-grams(SG): 预测上下文
- Continuous Bag of Words(CBOW):预测中心词
三种模型训练方法
3.1 朴素 softmax 法
计算一个词向量预测另一个词向量的概率,一种朴素的思想就是计算二者的相似度.
假设 $v_{c}$ 代表中心词, $u_{o}$ 代表其窗口中的一个词,则可以根据softmax的思想定义:
- 概率值定义:
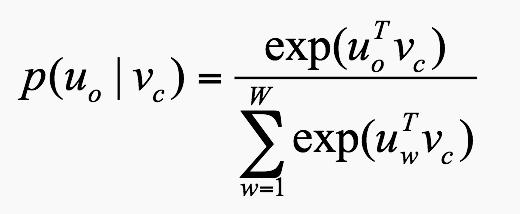
注意:这里W指的是语料字中所有的词量.
- 训练方法:SGD进行参数更新,但是并不像 BGD 那样对整个目标函数进行梯度下降,而是过滤一个窗口就进行一次更新
- 缺点:计算量大(每个窗口都进行更新);模型过于简单(仅仅利用两个词的相似度代表二者的预测概率);训练结束后,每个词对应于两个向量
3.2 Hierarchical softmax 法 (Huffman树)
huffman树最后导致的结果就是出现频率越高的词所在的子节点越靠近根部,词频出现的越低的词越靠近底部.
- 概率值定义:
假设这颗树有n个非叶子节点(标黄的部分) $R_i (i=1,…,n)$ ,
每个点处都有一个参 数$z_{i}$,其维度和词向量相同.每个节点都是一个类似LR的分类概率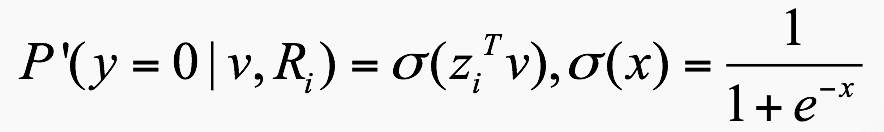
当中心词确定的时候,$v$ 就确定了,只有 $z$ 是要更新的参数,但最终的目标是求得最优的 $v$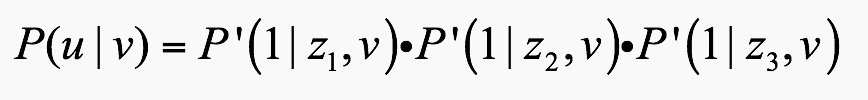
所以对每个窗口对应的
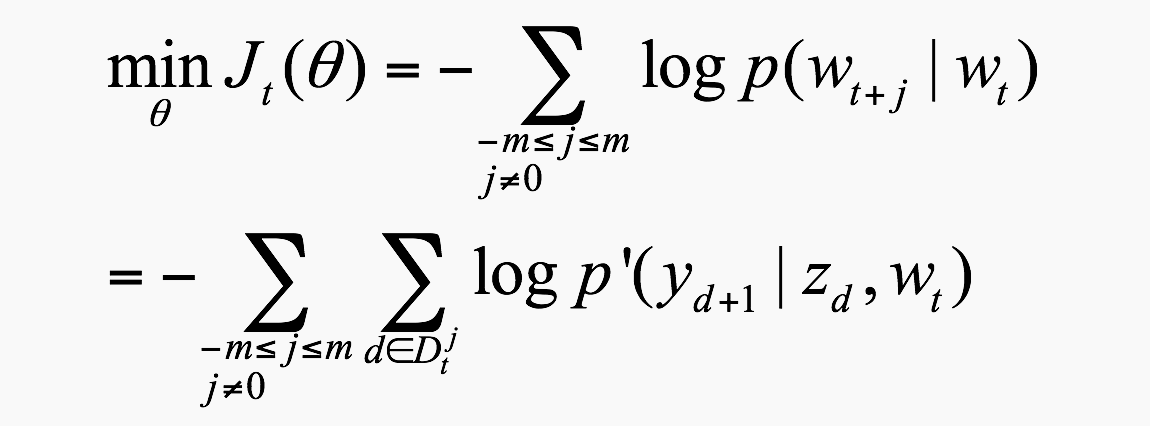
- 训练方法:SGD,
- 优点:模型复杂度低;预测概率更有解释性;训练完成后每个向量都对应到一个唯一的向量上
Huffman Tree1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55#Huffman Encoding
#Tree-Node Type
class Node:
def __init__(self,freq):
self.left = None
self.right = None
self.father = None
self.freq = freq
def isLeft(self):
return self.father.left == self
#create nodes创建叶子节点
def createNodes(freqs):
return [Node(freq) for freq in freqs]
#create Huffman-Tree创建Huffman树
def createHuffmanTree(nodes):
queue = nodes[:]
while len(queue) > 1:
queue.sort(key=lambda item:item.freq)
node_left = queue.pop(0)
node_right = queue.pop(0)
node_father = Node(node_left.freq + node_right.freq)
node_father.left = node_left
node_father.right = node_right
node_left.father = node_father
node_right.father = node_father
queue.append(node_father)
queue[0].father = None
return queue[0]
#Huffman编码
def huffmanEncoding(nodes,root):
codes = [''] * len(nodes)
for i in range(len(nodes)):
node_tmp = nodes[i]
while node_tmp != root:
if node_tmp.isLeft():
codes[i] = '0' + codes[i]
else:
codes[i] = '1' + codes[i]
node_tmp = node_tmp.father
return codes
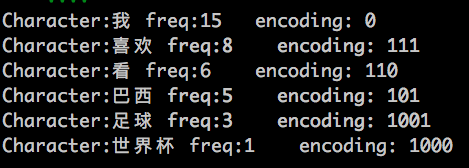
if __name__ == '__main__':
chars_freqs = [('我', 15), ('喜欢', 8), ('看', 6), ('巴西', 5), ('足球', 3), ('世界杯', 1)]
nodes = createNodes([item[1] for item in chars_freqs])
root = createHuffmanTree(nodes)
codes = huffmanEncoding(nodes,root)
for item in zip(chars_freqs,codes):
print 'Character:%s freq:%-2d encoding: %s' % (item[0][0],item[0][1],item[1])
3.3 Negative sampling 法
与 Hierarchical 法相比, 负采样法不再使用复杂的 huffman 树,而是采用随机负采样,这样的计算效率会得到进一步提升.
概率值定义:
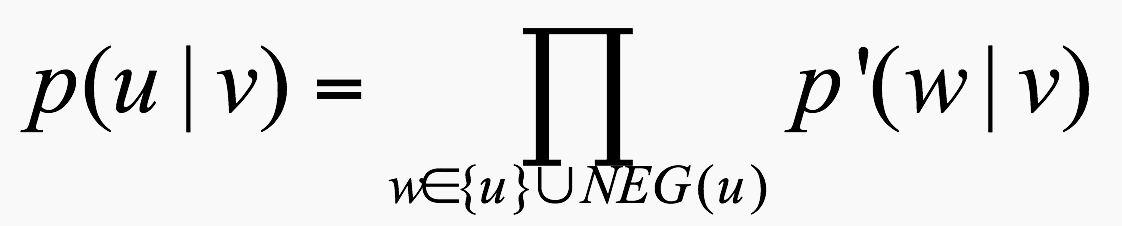
其中,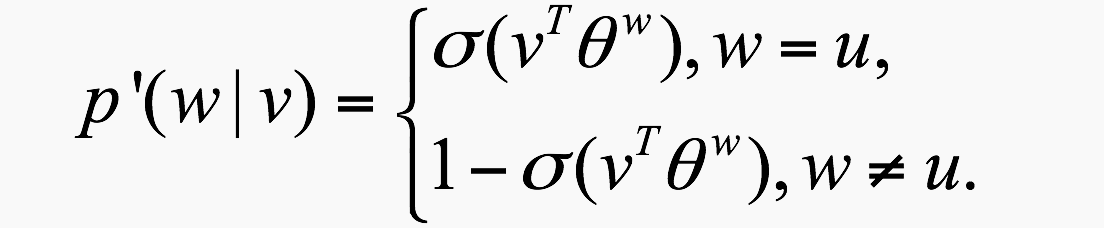
这里参数可以理解为每个词都对应了一个theta。当其作为正,负训练样本时便会得到更新。目标函数:此时的目标函数形式和 Hierarchical 的完全类似,唯一的区别就是 Hier 的概率表达式需要通过建立 huffman 树才能得到,而 NEG 法需要预先进行负采样.
- 负采样具体是如何进行的?就是最简单的线性加权采样的思想.比如说”我”出现3次,”你”出现1次,那么采样到”我”的概率为3/4.一般负采样集的元素个数为3个左右.
参数更新
GD Batch 过所有窗口进行更新 (BGD 指向最合适的,仅适用于凸函数)
SGD 过一个窗口进行更新 (折线走向,更新一次不需要那么久,不限于凸函数)